

I am currently a Senior Machine Learning Engineer at N-iX, contracting full-time for Cricut, and an Adjunct Professor of Computer Vision at the University of los Andes. I previously worked as a as a research assistant in computer vision at the CinfonIA research center of the University of los Andes in Bogota, Colombia under the supervision of Professor Pablo Arbeláez. I completed my Master's degree in Biomedical Engineering in 2024, supported and mentored by Google DeepMind, with research focused on medical applications of artificial intelligence. I also recieved my Honours Bachelor's degree in Biomedical Engineering with a double minor in Bioinformatics and Computational Mathematics in 2022. Over the past five years, I have worked on several research projects involving deep learning and computer vision for both medical and natural images. My main research interests include medical image analysis, image-guided surgical robot intelligence, multimodal learning, video understanding, generative AI, and vision-language models.
City: Bogotá D.C., Colombia
Zip Code: 110121
E-mail: nicoayobi@gmail.com
Find a more detailed report of my publications in my google scholar, my ResearchGate or my ORCID.
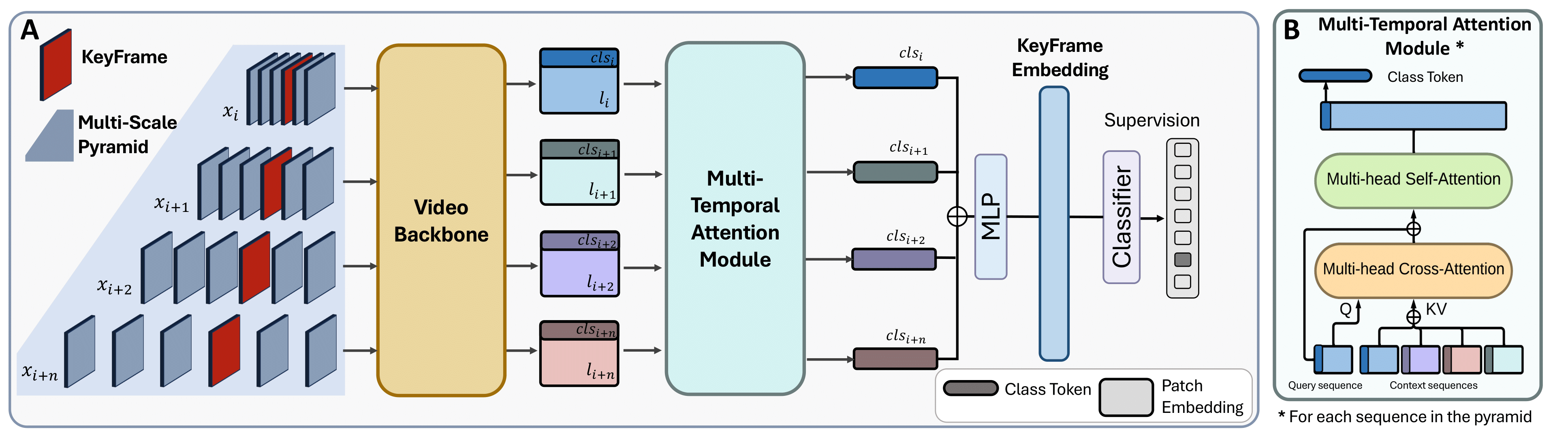
MuST: Multi-Scale Transformers for Surgical Phase Recognition.
Alejandra Pérez, Santiago Rodríguez, Nicolás Ayobi, Nicolás Aparicio, Eugénie Dessevres, and Pablo Arbeláez
Poster at the International Conference on Medican Image Computing and Computer Assisted Interventions (MICCAI) 2024.
[Paper]
[ArXiv]
[Code]
Phase recognition in surgical videos is crucial for enhancing computer-aided surgical systems as it enables automated understanding of sequential procedural stages. Existing methods often rely on fixed temporal windows for video analysis to identify dynamic surgical phases. Thus, they struggle to simultaneously capture short-, mid-, and long-term information necessary to fully understand complex surgical procedures. To address these issues, we propose Multi-Scale Transformers for Surgical Phase Recognition (MuST), a novel Transformer-based approach that combines a Multi-Term Frame encoder with a Temporal Consistency Module to capture information across multiple temporal scales of a surgical video. Our Multi-Term Frame Encoder computes interdependencies across a hierarchy of temporal scales by sampling sequences at increasing strides around the frame of interest. Furthermore, we employ a long-term Transformer encoder over the frame embeddings to further enhance long-term reasoning. MuST achieves higher performance than previous state-of-the-art methods on three different public benchmarks.
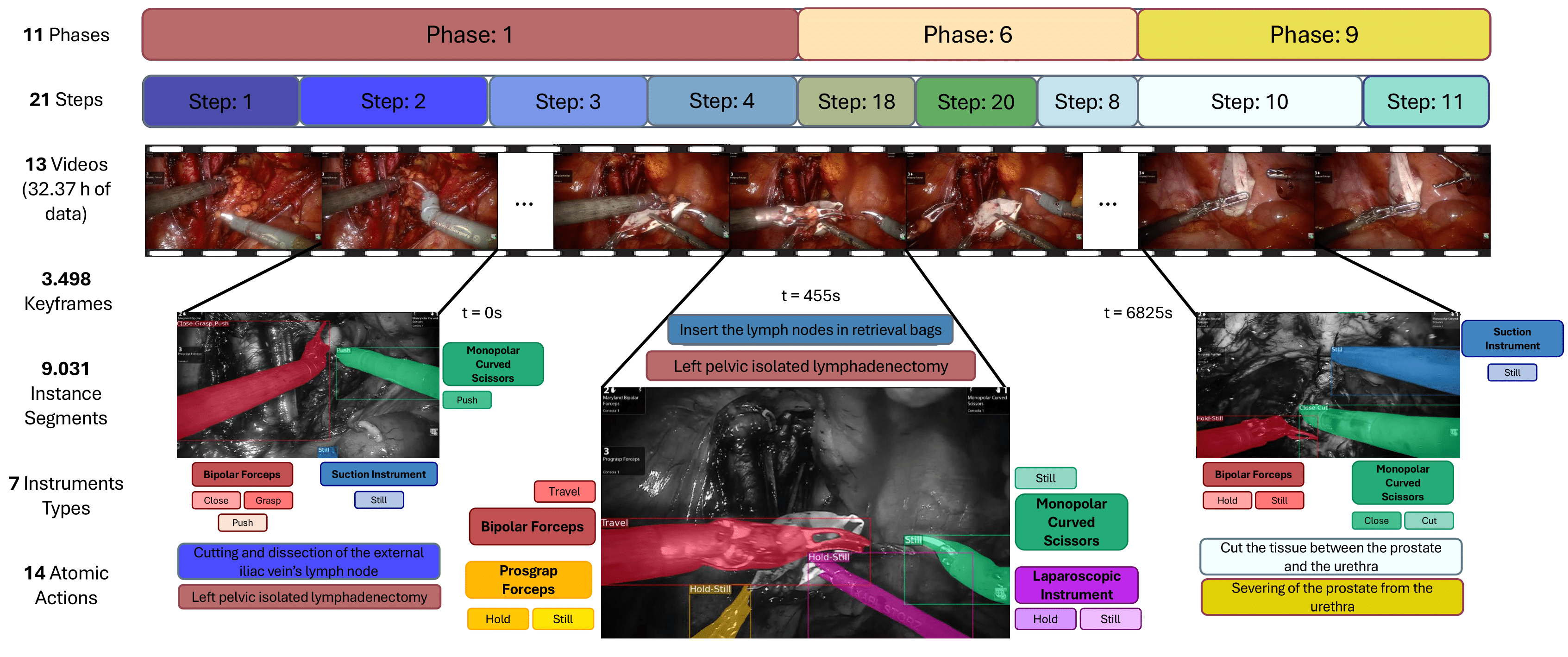
Pixel-Wise Recognition for Holistic Surgical Scene Understanding.
Nicolás Ayobi, Santiago Rodríguez, Alejandra Pérez, Isabela Hernández, Nicolás Aparicio, Eugenie Dessevres, Sebastián Peña, Jessica Santander, Juan Ignacio Caicedo, Nicolás Fernández, Pablo Arbeláez
Medical Image Analysis. Best Poster at Khipu AI 2025
[Paper]
[ArXiv]
[Code]
[Data]
This paper presents the Holistic and Multi-Granular Surgical Scene Understanding of Prostatectomies (GraSP) dataset, a curated benchmark that models surgical scene understanding as a hierarchy of complementary tasks with varying levels of granularity. Our approach encompasses long-term tasks, such as surgical phase and step recognition, and short-term tasks, including surgical instrument segmentation and atomic visual actions detection. To exploit our proposed benchmark, we introduce the Transformers for Actions, Phases, Steps, and Instrument Segmentation (TAPIS) model, a general architecture that combines a global video feature extractor with localized region proposals from an instrument segmentation model to tackle the multi-granularity of our benchmark. We demonstrate TAPIS’s versatility and state-of-the-art performance across different tasks through extensive experimentation on GraSP and alternative benchmarks. This work represents a foundational step forward in Endoscopic Vision, offering a novel framework for future research towards holistic surgical scene understanding.

STRIDE: Street View-based Environmental Feature Detection and Pedestrian Collision Prediction.
Cristina González*, Nicolás Ayobi*, Felipe Escallón, Laura Baldovino-Chiquillo, Maria Wilches-Mogollón, Donny Pasos, Nicole Ramírez, Jose Pinzón, Olga Sarmiento, D. Alex Quistberg, Pablo Arbeláez.
Oral presentation at the second ROAD++ workshop hosted at the International Conference of Computer Vision (ICCVW) 2023. Awarded Best Student Paper.
[Paper]
[ArXiv]
[Code]
[Data]
This paper introduces a novel benchmark to study the impact and relationship of built environment elements on pedestrian collision prediction, intending to enhance environmental awareness in autonomous driving systems to prevent pedestrian injuries actively. We introduce a built environment detection task in large-scale panoramic images and a detection-based pedestrian collision frequency prediction task. We propose a baseline method that incorporates a collision prediction module into a state-of-the-art detection model to tackle both tasks simultaneously. Our experiments demonstrate a significant correlation between object detection of built environment elements and pedestrian collision frequency prediction. Our results are a stepping stone towards understanding the interdependencies between built environment conditions and pedestrian safety.

PiGLET: Pixel-level Grounding of Language Expressions with Transformers.
Cristina González, Nicolás Ayobi, Isabela Hernández, Jordi Pont-Tuset, Pablo Arbeláez.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2023.
[Project Page]
[Paper]
[Code]
[Data]
This paper proposes Panoptic Narrative Grounding, a spatially fine and general formulation of the natural language visual grounding problem. We establish an experimental framework for the study of this new task, including new ground truth and metrics. We propose PiGLET a novel multi-modal Transformer architecture to tackle the Panoptic Narrative Grounding task, and to serve as a stepping stone for future work. We exploit the intrinsic semantic richness in an image by including panoptic categories, and we approach visual grounding at a fine-grained level using segmentations. In terms of ground truth, we propose an algorithm to automatically transfer Localized Narratives annotations to specific regions in the panoptic segmentations of the MS COCO dataset. PiGLET achieves a performance of 63.2 absolute Average Recall points. By leveraging the rich language information on the Panoptic Narrative Grounding benchmark on MS COCO, PiGLET obtains an improvement of 0.4 Panoptic Quality points over its base method on the panoptic segmentation task. Finally, we demonstrate the generalizability of our method to other natural language visual grounding problems such as Referring Expression Segmentation. PiGLET is competitive with previous state-of-the-art in RefCOCO, RefCOCO+, and RefCOCOg.
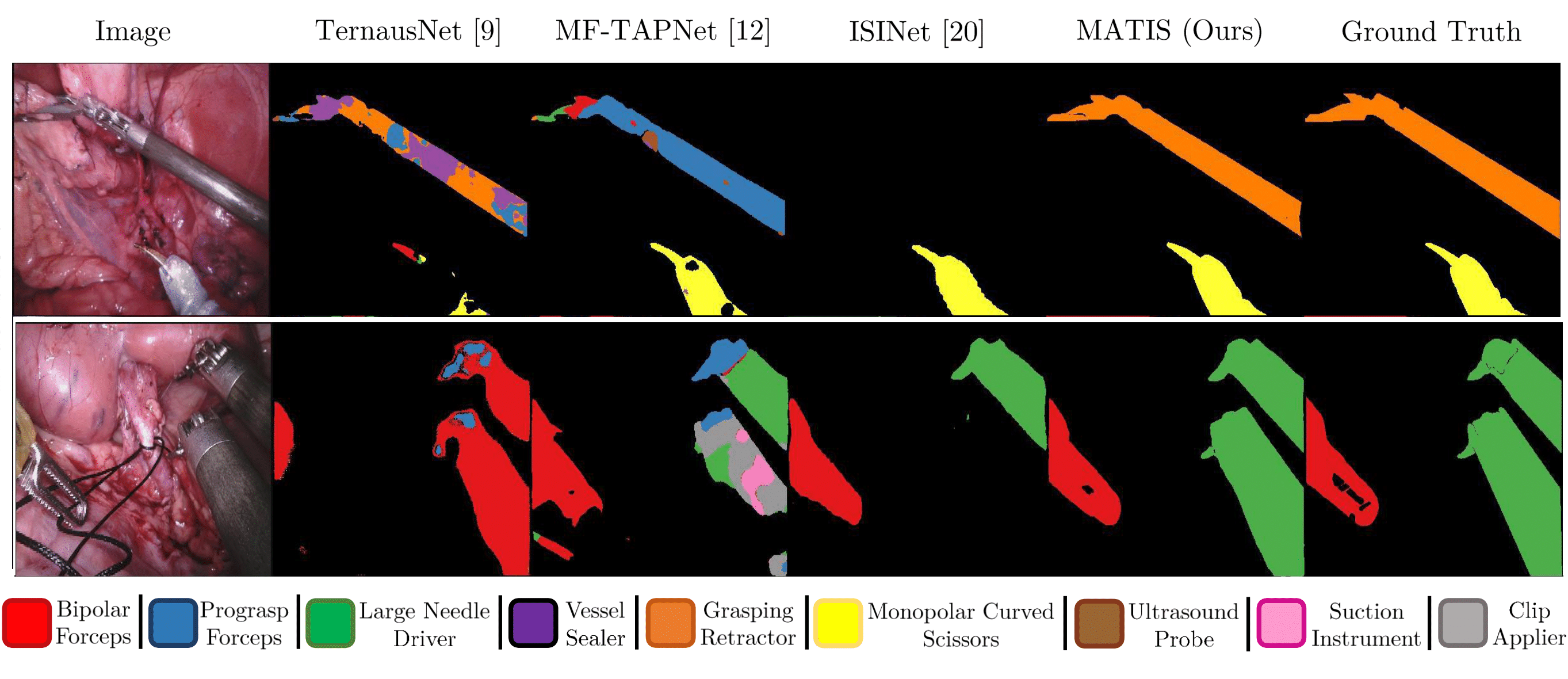
MATIS: Masked-Attention Transformers for Surgical Instrument Segmentation.
Nicolás Ayobi, Alejandra Pérez-Rondón, Santiago Rodríguez, Pablo Arbeláez.
Oral presentation at the IEEE International Symposium on Biomedical Imaging (ISBI) 2023.
[Paper]
[ArXiv]
[Code]
[Data]
We propose Masked-Attention Transformers for Surgical Instrument Segmentation (MATIS), a two-stage, fully transformer-based method that leverages modern pixel-wise attention mechanisms for instrument segmentation. MATIS exploits the instance-level nature of the task by employing a masked attention module that generates and classifies a set of fine instrument region proposals. Our method incorporates long-term video-level information through video transformers to improve temporal consistency and enhance mask classification. We validate our approach in the two standard public benchmarks, Endovis 2017 and Endovis 2018. Our experiments demonstrate that MATIS’ per-frame baseline outperforms previous state-of-the-art methods and that including our temporal consistency module boosts our model’s performance further.
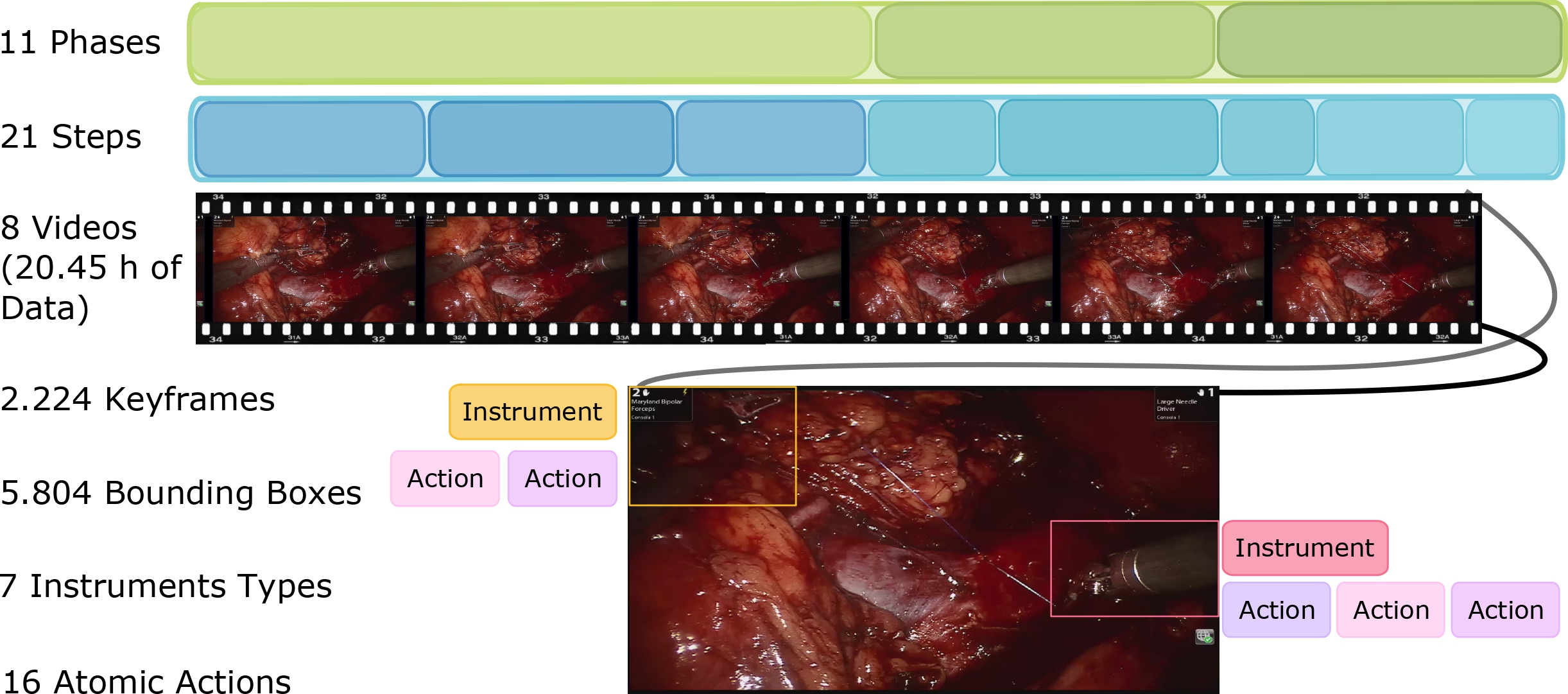
Towards Holistic Surgical Scene Understanding.
Natalia Valderrama, Paola Ruíz, Isabela Hernández, Nicolás Ayobi, Mathilde Verlyk, Jessica Santander, Juan Caicedo, Nicolás Fernández, Pablo Arbeláez.
Oral Presentation at the International Conference on Medican Image Computing and Computer Assisted Interventions (MICCAI) 2022. Nominated for Best Paper Award.
[Project Page]
[Paper]
[ArXiv]
[Code]
[Data]
Most benchmarks for studying surgical interventions focus on a specific challenge instead of leveraging the intrinsic complementarity among different tasks. In this work, we present a new experimental framework towards holistic surgical scene understanding. First, we introduce the Phase, Step, Instrument, and Atomic Visual Action recognition (PSIAVA) Dataset. PSI-AVA includes annotations for both long-term (Phase and Step recognition) and short-term reasoning (Instrument detection and novel Atomic Action recognition) in robot-assisted radical prostatectomy videos. Second, we present Transformers for Action, Phase, Instrument, and steps Recognition (TAPIR) as a strong baseline for surgical scene understanding. TAPIR leverages our dataset’s multi-level annotations as it benefits from the learned representation on the instrument detection task to improve its classification capacity. Our experimental results in both PSI-AVA and other publicly available databases demonstrate the adequacy of our framework to spur future research on holistic surgical scene understanding.

Panoptic Narrative Grounding.
Cristina González, Nicolás Ayobi, Isabela Hernández, José Hernández, Jordi Pont-Tuset, Pablo Arbeláez.
Oral presentation at the International Conference of Computer Vision (ICCV) 2021.
[Project Page]
[Paper]
[ArXiv]
[Code]
[Data]
This paper proposes Panoptic Narrative Grounding, a spatially fine and general formulation of the natural language visual grounding problem. We establish an experimental framework for the study of this new task, including new ground truth and metrics, and we propose a strong baseline method to serve as stepping stone for future work. We exploit the intrinsic semantic richness in an image by including panoptic categories, and we approach visual grounding at a fine-grained level by using segmentations. In terms of ground truth, we propose an algorithm to automatically transfer Localized Narratives annotations to specific regions in the panoptic segmentations of the MS COCO dataset. To guarantee the quality of our annotations, we take advantage of the semantic structure contained in WordNet to exclusively incorporate noun phrases that are grounded to a meaningfully related panoptic segmentation region. The proposed baseline achieves a performance of 55.4 absolute Average Recall points. This result is a suitable foundation to push the envelope further in the development of methods for Panoptic Narrative Grounding.
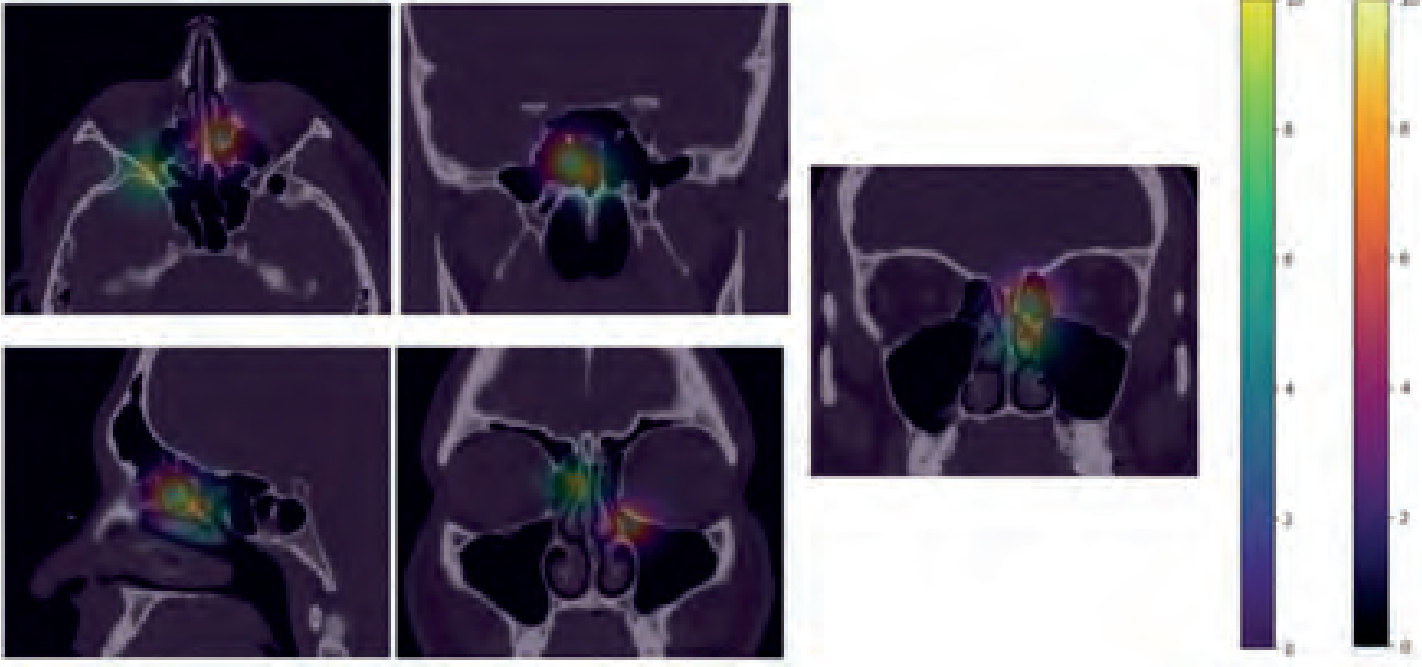
Development of a Movil App for the Preoperative Evaluation of Sinus CT Scan: One Step Towards Artificial Intelligence.
Javier Ospina, Cristhian Forigua, Andrés Hernández, Nicolás Ayobi, Tomás Correa, Augusto Peñaranda, Arif Janjua.
Oral presentation at Acta de Otorrinolaringología y Cirugía de Cabeza y Cuello 2022.
[Paper]
The recent technology revolution that we have experienced has generated extensive interest in the use of artificial intelligence (AI) in the development of various systems and solutions in medicine. In the field of Otorhinolaryngology, we are seeing the first efforts to take advantage of this flourishing area. Objective: We sought to describe the development process of a mobile app created through a collaborative effort between ENT surgeons and biomedical engineers. This app has the intention to optimize the preoperative evaluation of paranasal sinus tomography (CT) to improve safety and outcomes in Endoscopic Sinus Surgery (ESS). Methods: The development of the app followed the prioritization method for MoSCoW specifications. We used the information collected from surveys of 29 Rhinology experts from different parts of the world, who evaluated anatomical variants on sinus CT scans. Two regression models were used to predict difficulty and risk using statistical learning. Conclusion: Via statistical modelling, we have developed a user-friendly tool that will ideally help surgeons assess the risk and difficulty of ESS based on the pre-operative CT scan of the sinuses. This is an exercise that demonstrates the efficacy of the collaborative efforts between surgeons and engineers to leverage AI tools and promote better solutions for our patients.
June 2023 - August 2023
~ Research Summer School of Introduction to Deep Learning
August 2022 - December 2022
~ Advanced Machine Learning
January 2022 - June 2022
~ Computer Vision
January 2022 - September 2022
~ Coursera's Master's Degree in AI by Uniandes
November 2021 - December 2021
~ Coursera's Master's Degree in AI by Uniandes
August 2021 - December 2021
~ Introduction to Programming
January 2021 - June 2021
~ Data Structures and Algorithms (Python)
August 2020 - June 2021
~ Data Structures (Java)
August 2020 - December 2020
~ Image Analysis and Processing
January 2020 - June 2020
~ Biomedical Engineering Foundations for Neurosurgery
Double minor in Computational Mathematics and in Bioinformatics